
Dr Klaus Schulz | Dr Florian Fink – Novel Software for Cleansing Digitised Historical Texts
A fortune in historical information lies in archives and library basements around the world. Now, research by Dr Klaus Schulz, Dr Florian Fink and their colleagues at Ludwig-Maximilians-Universität in Munich is helping to bring this important information to light.
Digital Textual Archaeology
The traces of the past can be found everywhere – in buildings, in the rings of trees, in layers of ice. Yet the most useful traces are those that were deliberately made – documents written by those in the past to record their daily lives and momentous experiences. Much of this information lies in archives and the cellars of libraries, hidden away from the sunlight and from those who would most like to read it.
Yet this is changing. The ability to scan and digitalise documents means that this precious information can be taken from the archive and sent around the globe with the click of a button. Researchers can track information, correlate discoveries, and identify unexpected variations in the historical record – all from the comfort of their own offices. This has been described as digital (textual) archaeology, in which those who explore texts of the past are more often found at their laptops than in front of old books in library cellars.
The technology underlying this digital archaeology is known as optical character recognition, or OCR. OCR is the process by which a printed text is scanned as an image and then converted into a computer-legible format – a process that involves automated detection of the ‘shape’ of the letters in the image and cross-referencing to a database of letters. By comparing one to another, the computer can make an accurate guess as to the letters and words present in the scanned text.
This sounds simple enough, and indeed is comparatively easy when scanning printed documents or those documents with a standardised layout and clear writing. Unfortunately, most historical documents are not clear – they are handwritten, have various degrees of damage or discoloration, and often use cursive loops or unusual handwriting styles. This problem is not confined to handwritten text alone – even printed books show a surprising amount of variation in fonts and legibility. Thus, historians have been somewhat abandoned by the technological advances possible by OCR, and indeed it is only in recent decades that the technique has truly caught on in the field.
E-book

Reference
https://doi.org/10.26320/SCIENTIA278
Share
{kind=link}

The rush into OCR has led to reams of documents that need to be accurately digitised. This has spurred other researchers to develop tools that allow this digitisation to proceed in a rapid and efficient way. Dr Klaus Schulz and Dr Florian Fink of the internationally renowned Ludwig-Maximilians-Universität in Munich have set out to support those who are involved in the digitisation process. ‘We are developing user-friendly web-based systems,’ says Dr Schulz, ‘allowing interactive and automated post-correction that takes into account the immense range of spelling variations typically found in historical texts.’
Post-Correction
Modern algorithms and programs for OCR are exceptionally good, often able to accurately identify individual characters 95% of the time. This is enough for many purposes, but often a historical researcher will need perfect accuracy – a text that they are certain has been encoded with 100% fidelity. This is a far more difficult process and requires that the encoded text be updated after the scan – a process known as post-correction. Unfortunately for researchers, fully automated post-correction tends to be ineffective. Minor mistakes in the software’s judgement will lead to the incorporation of even more errors – often at a higher rate than the removal of the previous errors.
To avoid this, the majority of post-correction is performed by humans, usually in conjunction with some sort of software assistance. ‘By using OCR, all printed materials available in historical archives can be transformed into web-searchable text, but results from historical documents are often unsatisfactory, and thus intelligent systems for post-correction are needed to help restore original documents and reach the quality needed,’ notes Dr Schulz.
One area in which this is particularly challenging is that of spelling – modern spelling is significantly different to that used in the past. This is particularly noticeable when looking at documents from previous centuries, at which time the language was both very different and far more heterogeneous than the modern equivalent. This can easily be seen by comparing a bible passage: ‘Jesus went throughout every city and village’, to the Middle English equivalent ‘Jhesu made iorney by citees and castelis’. Similarly, studies of old texts show that authors used befor, beforn, bifor, biforn, byfor, byfore and byforn where we would now simply write ‘before’.
To help solve these problems, Dr Schulz, Dr Fink and their colleagues have developed an intelligent assistant. As Dr Schulz explains, this post-correction software intelligently analyses OCR-output by using a technique that provides a statistical profile of words and word series that are likely to be OCR-errors. Their software thus notes these likely errors and is able to provide suggestions that take historical spelling variation into account.

Intelligent Software
This sounds rather complicated, and indeed it is. At heart, however, the team’s software can be thought of as assessing two interacting models as the document is digitalised and checked. These two models, known as the global and the local profile, provide an intelligent process for determining just what words are being scanned. More importantly, they do this in a highly automated and efficient manner.
One part of the software develops what is referred to as a global profile – one that covers the entire document or series of documents being analysed. This includes several important factors that help to improve overall accuracy, of which two are highly important. First, the typical recognition errors that are seen in the document are listed, by frequency, to give an approximate idea of how likely any particular mistake would be. Second, the typical variations in spelling observed in documents of that era are listed, including the number seen in that particular document, to help define when an occurrence is an error and when it is a spelling variation.
The other part of the team’s software is known as the local profile, which is specific to each token, or ‘chunk’ of text being analysed. This local profile consists of a ranked list of possible interpretations for the section that is being assessed – a smudged word may be considered to probably represent ‘boat’, but may also represent ‘boot’, ‘bode’ or ‘beat’. The computation of the local profile combines rule-based lexicographic methods with statistical adjustments.
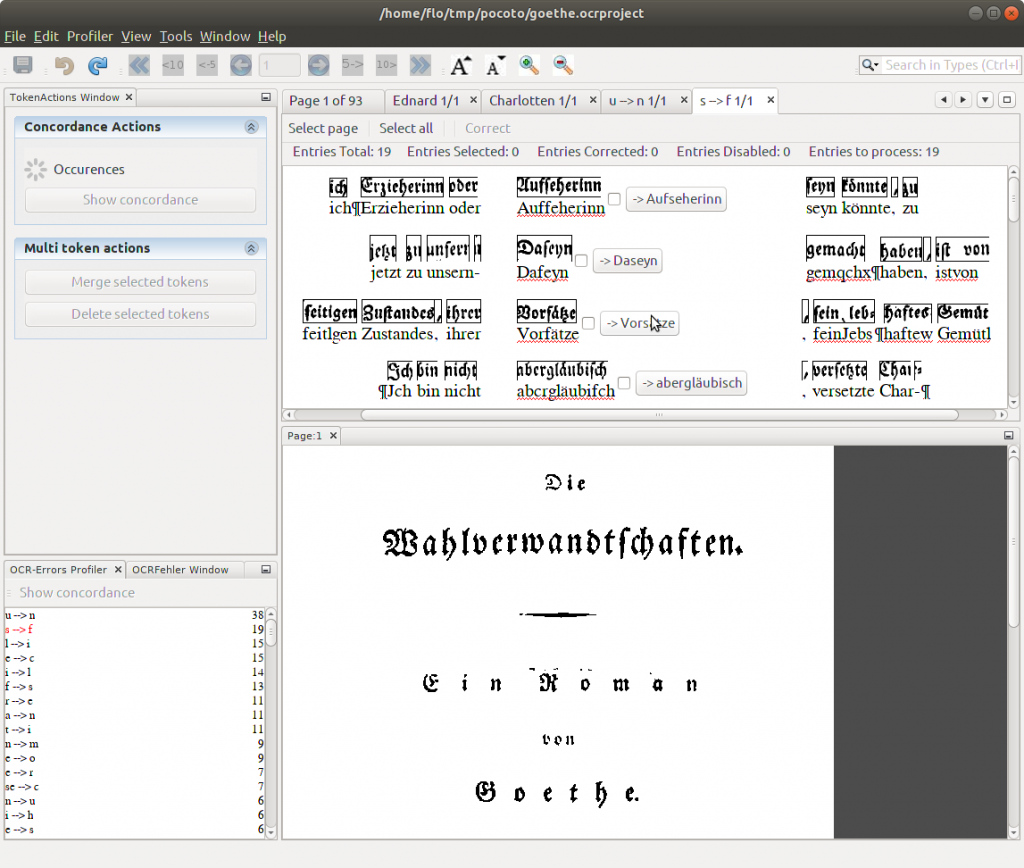
The combination of the two profiles allows the software to intelligently adjust assessments based on the characteristics of the document. In other words, a document that is known to consistently contain a certain spelling variant (stored in the global profile) will be able to adjust the ranking of possible interpretations in the local profile to favour this variant (or, vice versa, to ignore an unlikely variant).
Further improvements come when feedback from the user is incorporated into this learning approach. Each document is checked manually by an experienced reader, usually focusing their attention on areas that have been flagged by the software as somehow standing out of the normal next. These are often errors or incorrect assignments of words. By checking the document scan itself, the user is able to determine what the correct word should be and manually correct the digitalised version to fix the mistake.
This information is then fed back into the software and allows ‘batch correction’ of errors. For example, the same word may be consistently recognised as another – this occurrence can be flagged and corrected throughout the document with a few mouse clicks. Even more usefully, it is also possible to correct similar errors of the same type within different words. For example, the letters ‘u’ and ‘n’ are often confused when scanned from older texts, particularly those in heavily stylised fonts. The software allows these errors to be batch corrected, using a best-estimate guess of which words are misspelled.
The team’s software also allows implementation of automated learning behaviour. In other words, the software flags potential errors and these are corrected by the human reader. This leads to an update in the global profile, noting that a particular error is more likely to occur within the document. This information feeds back into the local profile, providing an increased ‘confidence’ that one interpretation of the text is the correct one.
Why is this so important? The combination of profiling and machine learning means that a scanned text can be encoded to a high level of quality within a very short period of time. Indeed, as Dr Schulz notes, the software ‘directly indicates conjectured errors and can efficiently correct complete series of OCR errors, offering excellent features for machine-learning-based automated correction.’ This allows for the rapid digitisation of historical texts, thus bringing this once-hidden information to the world.
Reading the Words of Tomorrow
Where do the researchers intend to go from here? One potential area is that of automated categorisation. Although converting a document into machine-readable format is comparatively straightforward, actually understanding that text is a much harder job. Thus, the next frontier is the ability to assess the content of the historical document and assign categories and other useful metadata without human intervention.
The work of Dr Schulz, Dr Fink and their colleagues is the foundation for the spin-off company TopicZoom, which has commercialised technology for extracting information from unstructured documents (reports, articles and most of the other documents we deal with in daily life). By using this technology, in combination with their OCR software, the team was able to automate the identification of relevant topics even within old and corrupted documents.
This naturally opens up a whole new vista of automation, a true ‘digital textual archaeology’ in which computational linguistics performs the grunt work while the researchers can focus their limited time and energy on the important work – that of posing hypotheses, finding data and solving problems.
Meet the researchers

Dr Klaus U. Schulz
Centrum für Informations- und Sprachverarbeitung
Ludwig-Maximilians-Universität
Munich
Germany
Dr Klaus Schulz began his career in the traditional university town of Tübingen, where he gained his PhD in mathematics in 1987, while at the same time working in computational linguistics. After working as a visiting professor in Rio de Janeiro, he moved back to Tübingen to complete the post-doctoral qualification known as a habilitation. In 1991, he started his current role as a Professor of Computational Linguistics in the prestigious Ludwig-Maximilians-Universität (LMU) in Munich. A research career spanning over 30 years and more than 100 publications has eventually led him to his current focus – that of digital libraries, improvement of document analysis, and semantic search algorithms.
W: http://www.cis.uni-muenchen.de/people/schulz.html

Dr Florian Fink
Centrum für Informations- und Sprachverarbeitung
Ludwig-Maximilians-Universität
Munich
Germany
Dr Florian Fink was awarded his Master of Arts in Computational Linguistics at the Centrum für Informations- und Sprachverarbeitung (CIS), Ludwig-Maximilians-Universität Munich, in 2012. He subsequently went on to pursue a PhD degree under the supervision of Dr Klaus Schulz at the world-renowned Ludwig-Maximilians-Universität (LMU) in Munich, which he completed in 2018. Alongside his PhD research, he also worked as a teacher in Computational Linguistics at the Centrum for Informations- und Sprachverarbeitung at LMU. He currently works as a Scientific Assistant at the same institution, where his research interests include digital libraries and improving the analysis of historical documents.
CONTACT
E: flo@cis.lmu.de
W: http://www.cis.uni-muenchen.de/personen/mitarbeiter/fink/index.html
FUNDING
The group’s work in the field of postcorrection was funded by EU Project Impact ‘Improving Access to Text’ (2008-2013), Clarin (CLARIN-DE-FAG4-KP3, 2015-2016), and the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) – Projektnummern 393215159, 314731081 (2016–2019).
KEY COLLABORATORS
Tobias Englmeier (CIS, LMU)
Dr Annette Gotscharek*
Dr Uli Reffle*
Dr Christoph Ringlstetter*
Dr Uwe Springmann*
Thorsten Vobl*
*former CIS members
![]()